![]()
ทีม DeepMind ของกูเกิ้ล (Google) ได้เปิดเผย Transframer ซึ่งเป็นปัญญาประดิษฐ์ที่สามารถสร้างวิดีโอความยาว 30 วินาทีจากรูปภาพนิ่ง 1 รูปได้ โดยไม่ต้องการรายละเอียดข้อมูลรูปทรงทางเรขาคณิต เมื่อ Transframer ได้รับรูปภาพ ๑ รูปมาแล้วจะนำภาพนั้นไปวิเคราะห์และสร้างภาพเคลื่อนไหวจากบริบทโดยรอบ และแสดงภาพหลายมุมมอง Transframer จะวิเคราะห์บริบทของภาพพร้อมกับปัจจัยต่างๆ เช่น เวลา มุมกล้อง เพื่อทำนายความน่าจะเป็นของวัตถุ
กูเกิ้ลมีเป้าหมายที่จะพัฒนา Transframer ให้สามารถทำงานได้ตั้งแต่การทำนายภาพที่จะเกิดขึ้นในอนาคต การเปลี่ยนมุมของวัตถุ การแสดงภาพแบบ Multi-task Vision (Multi-task Vision คือการวิเคราะห์ภาพในมุมมองหลายๆ มิติเพื่อนำมาสร้างเป็นภาพใหม่ เช่น การแสดงภาพด้วยมิติระดับความลึก มิติการแบ่งส่วนภาพ หรือมิติการตรวจจับวัตถุในภาพ)
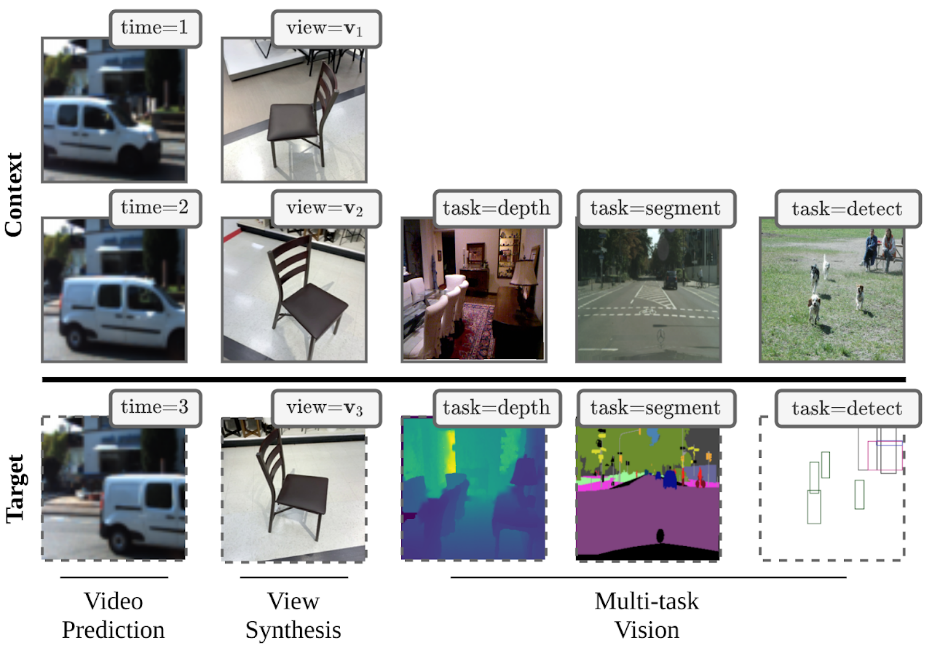
ตัวอย่างผลลัพธ์ของ Transframer ในการสร้างภาพวิดีโอจากภาพนิ่ง
หลักการทำงานของ Transframer คือการรวมเอาปัญญาประดิษฐ์ที่ทำงานแตกต่างกันมาทำงานร่วมกัน เช่น การแบ่งส่วนภาพ การสร้างภาพมุมมองต่างๆ การแทรกภาพระหว่างภาพแรกและภาพสุดท้ายของวิดีโอ เพื่อให้วิดีโอเคลื่อนไหวอย่างต่อเนื่องมากขึ้น ซึ่ง Transframer ทำนายรูปภาพได้ 8 แบบ เช่น การแบ่งส่วนภาพ (Semantic Segmentation) การจำแนกประเภทรูปภาพ (Image Classification) การทำนายจุดรวมสายตา (Optical Flow Prediction) การแสดงวัตถุในหลายมุมมองจากโมเดลรูปภาพ (Video Modeling) การตรวจจับวัตถุ (Detection)

ตัวอย่างความสามารถของ Transframer
เว็บไซต์ futurism ให้ข้อสังเกตว่า Transframer จะเพิ่มทางเลือกใหม่ในการสร้างวิดีโอเกม ให้สามารถใช้ปัญญาประดิษฐ์สร้างภาพบรรยากาศดิจิทัลโดยไม่ต้องรอการสร้างภาพด้วยวิธีอื่นที่ใช้เวลามากกว่า และจะเป็นการบุกเบิกแนวทางใหม่ของศิลปะ การวิเคราะห์ทางวิทยาศาสตร์ และการพัฒนาของปัญญาประดิษฐ์ในอนาคต
ที่มา : https://www.popsci.com/technology/one-image-video-deepmind/





